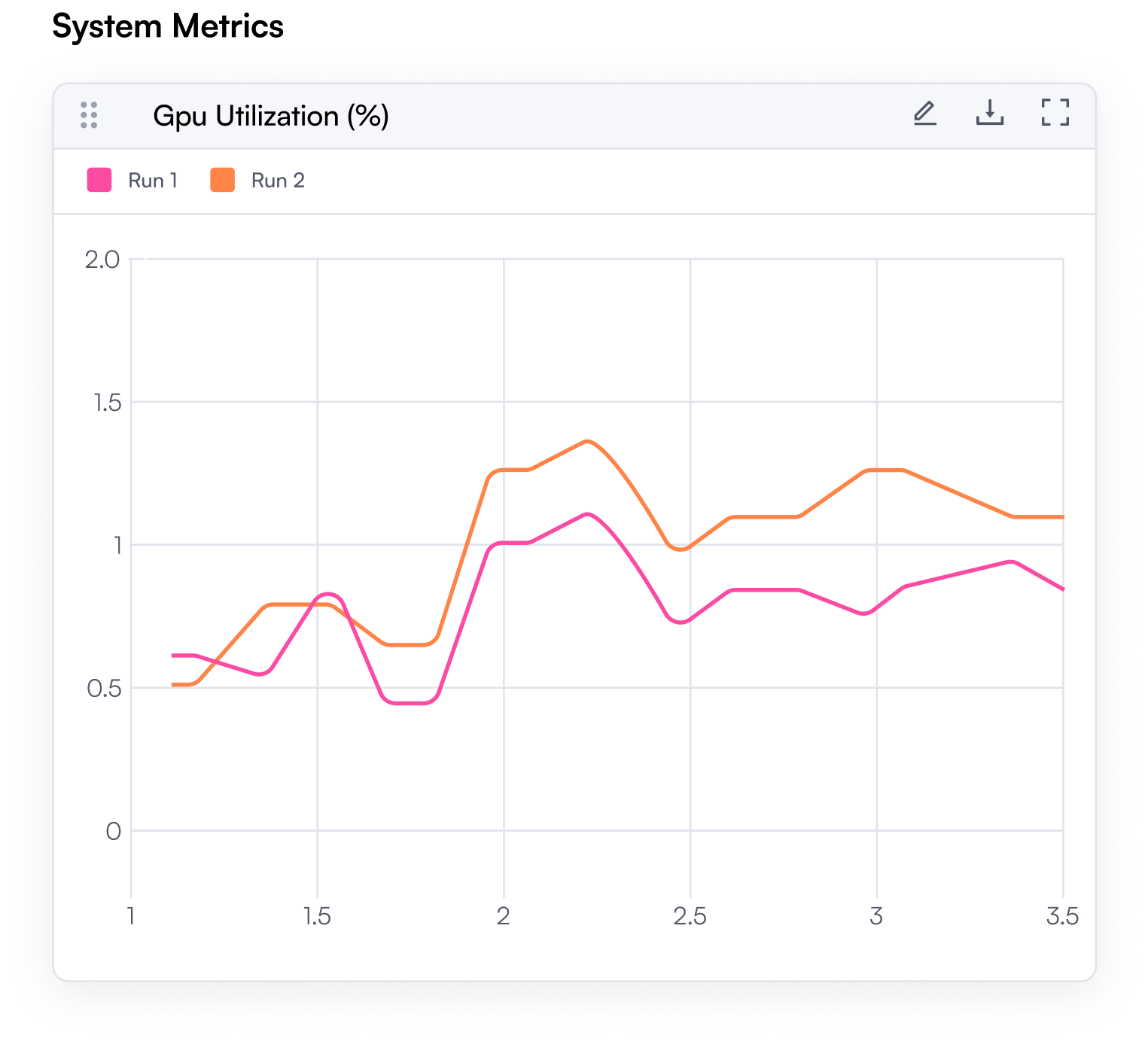
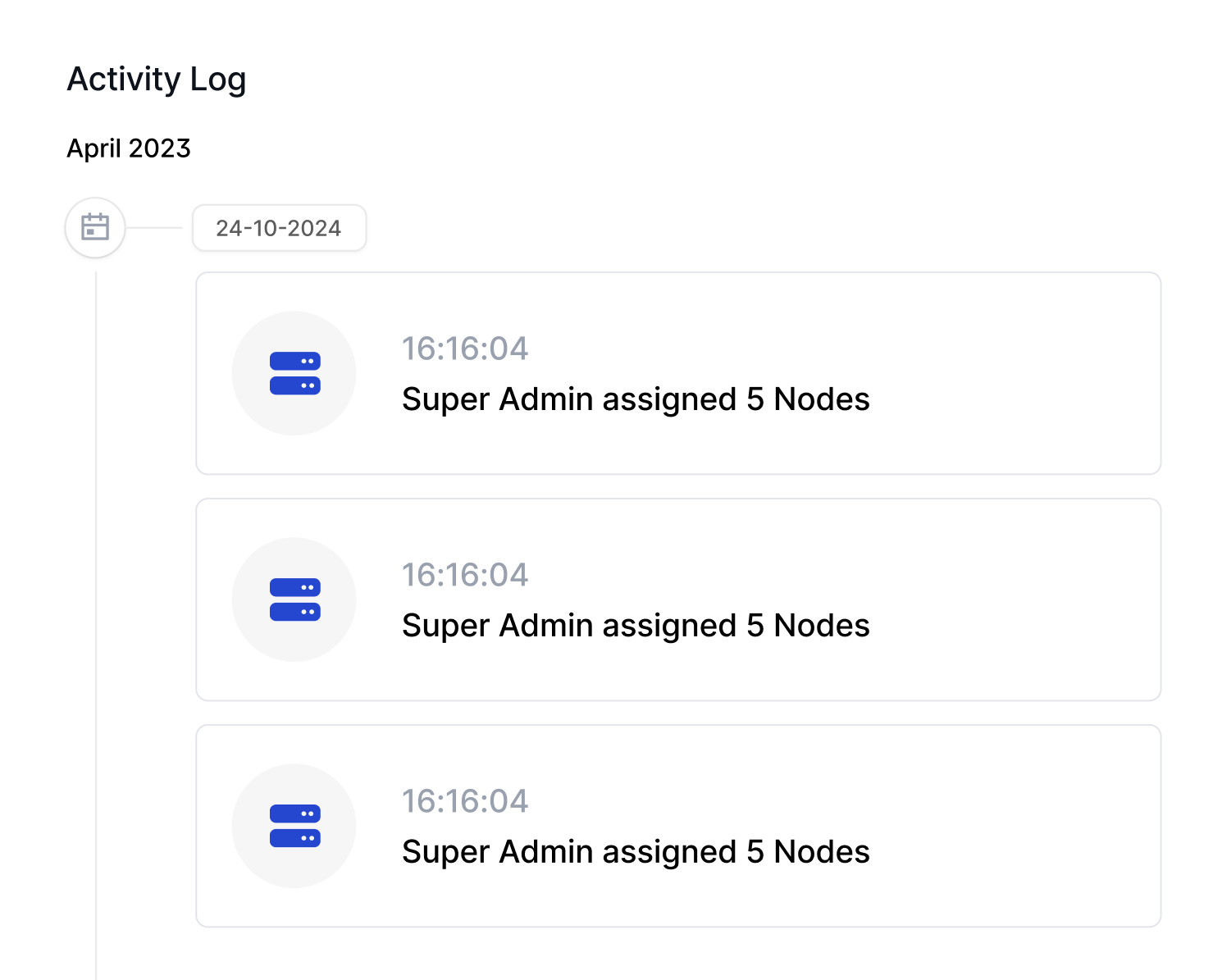
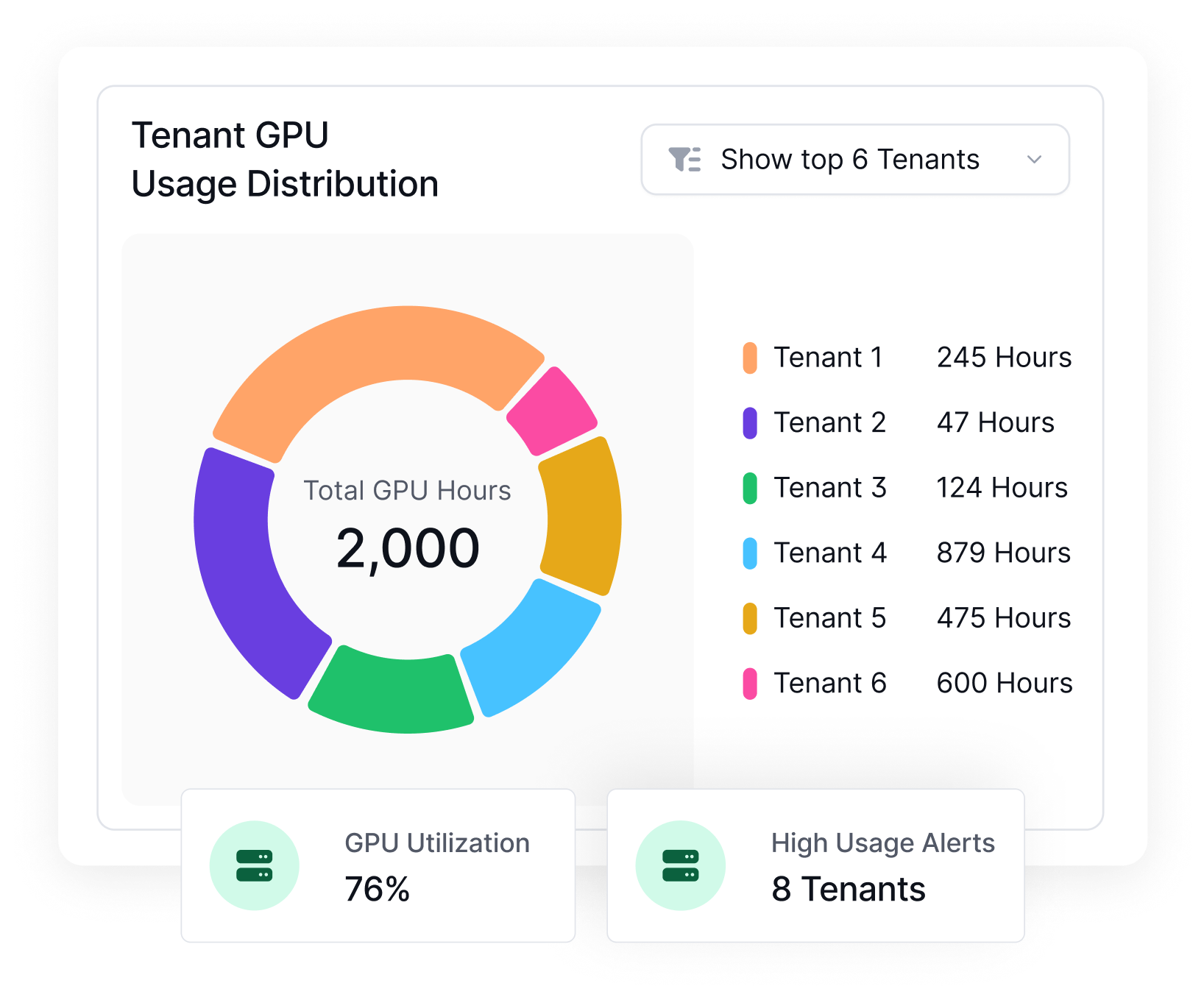
Built-in multi-tenancy, RBAC, and governance tools
02
Scalable & Accelerator-Agnostic
Supports any GPU provider without vendor lock in
03
AI Performance Optimization
Intelligent workload scheduling and resource management
04
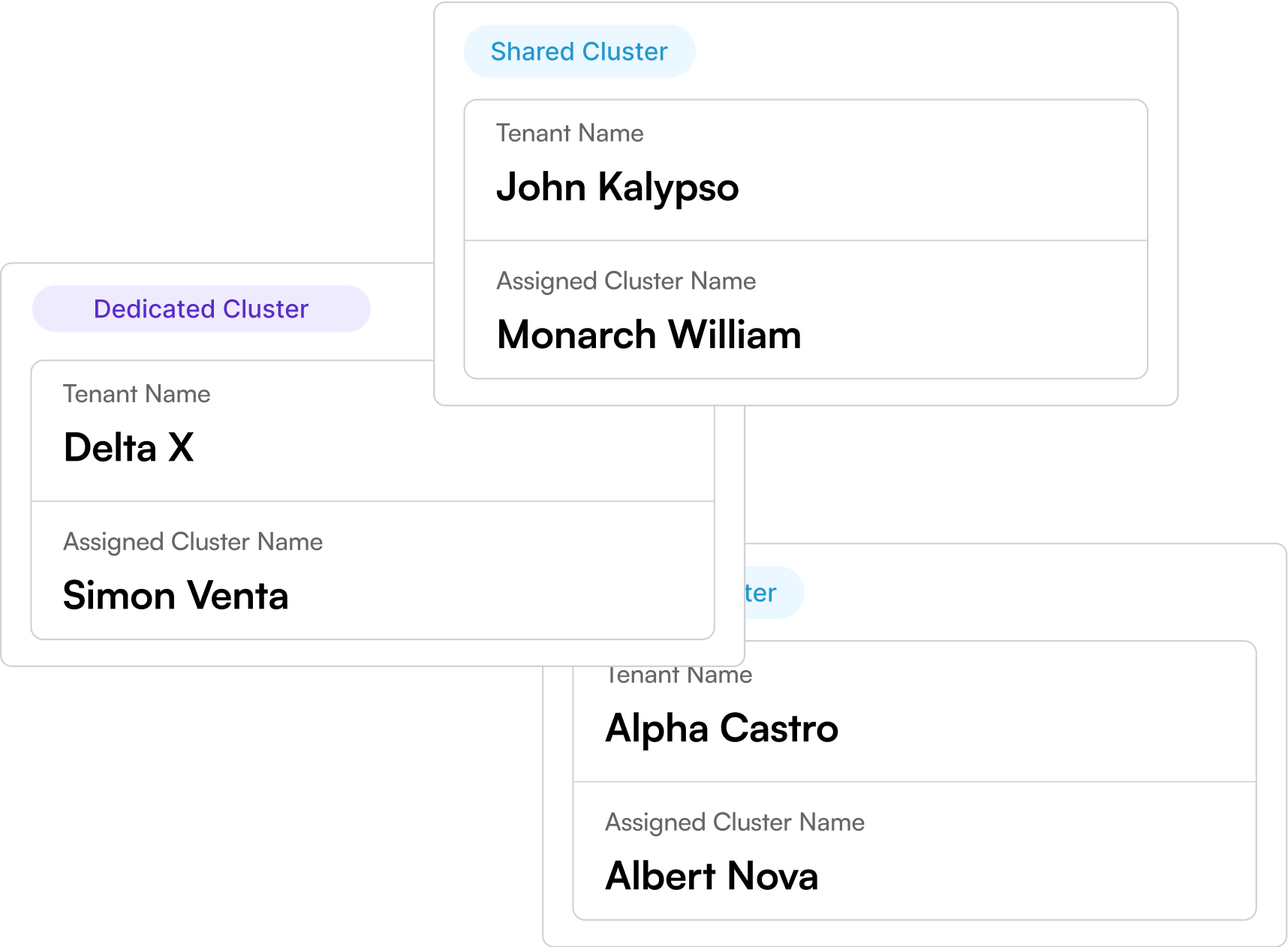
Multi-Cluster AI Orchestration
Orchestrate AI workloads across clusters with full control.
Performance
Time-to-Deploy
0X
From provisioning to production-ready LLM workflows, in hours, not weeks.
Higher GPU Utilization
0%
Maximize usage with multi-tenancy, job-aware scheduling, and GPU fractioning.
Cost Efficiency
0X
Optimize for per-second GPU billing and auto-scaling with zero idle capacity.
Infra Sovereignty
0%
Deploy on your own cloud, region, or bare-metal servers, no lock-in.
OICM – AI Infrastructure Orchestration
A secure, flexible platform to orchestrate GPU infrastructure across multi-tenant, multi-cluster, and multi-cloud environments
Let’s Dive Deeper
01
Cluster Manager
Secure & seamless AI workload orchestration with multi-tenancy, resource isolation, and dynamic scheduling.
02
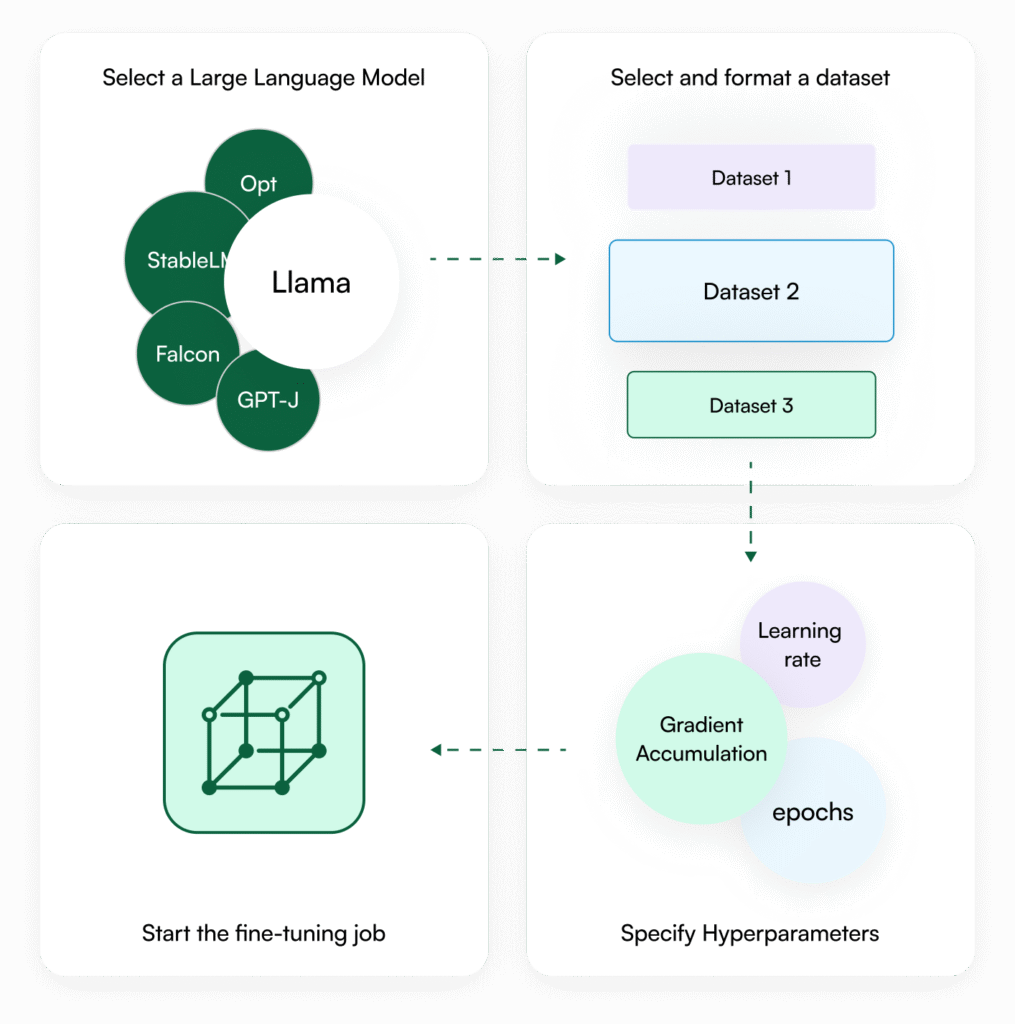
MLOps / LLMOps
Streamlined AI development with experiment tracking, LLM fine-tuning, and automated model deployment.
03
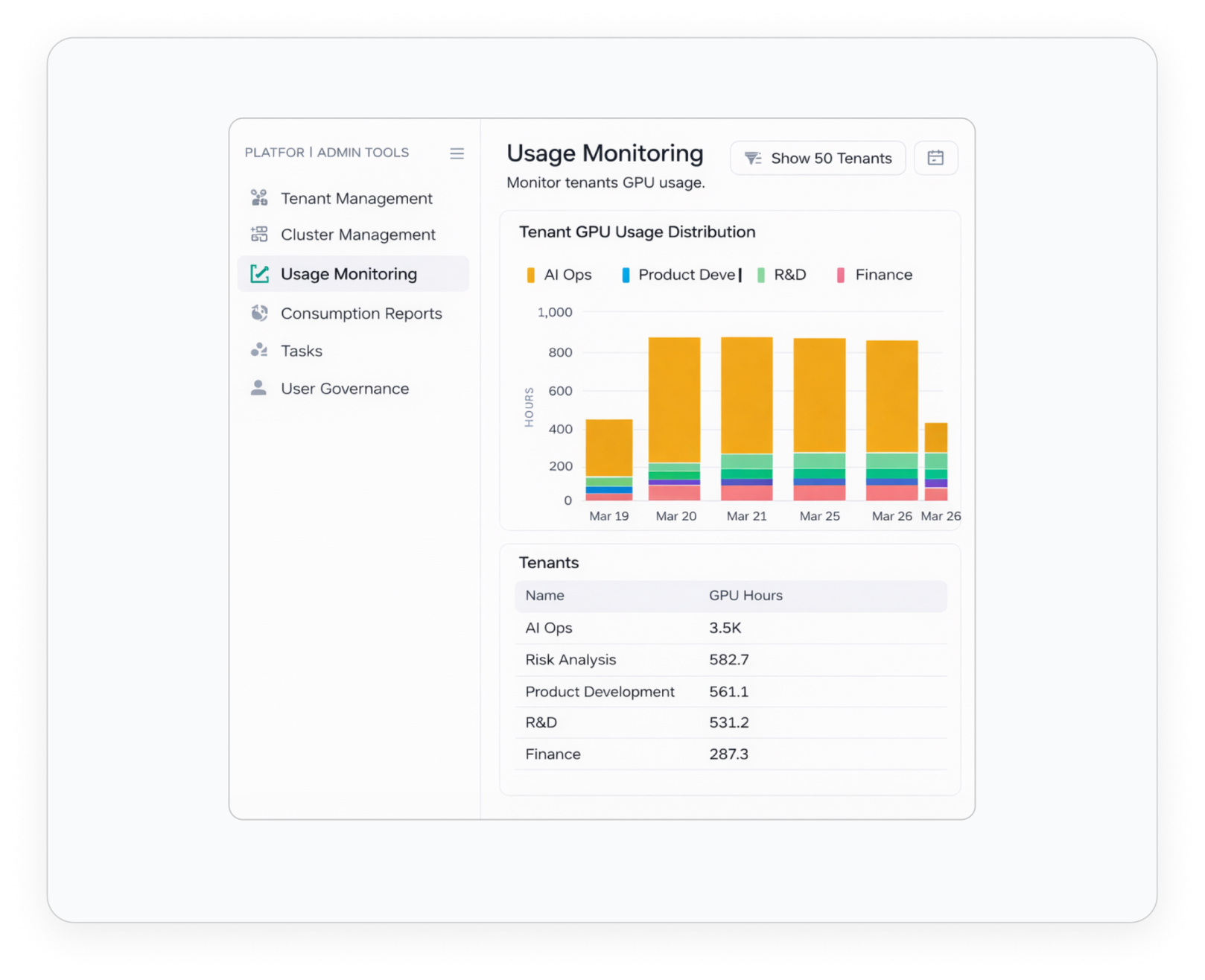
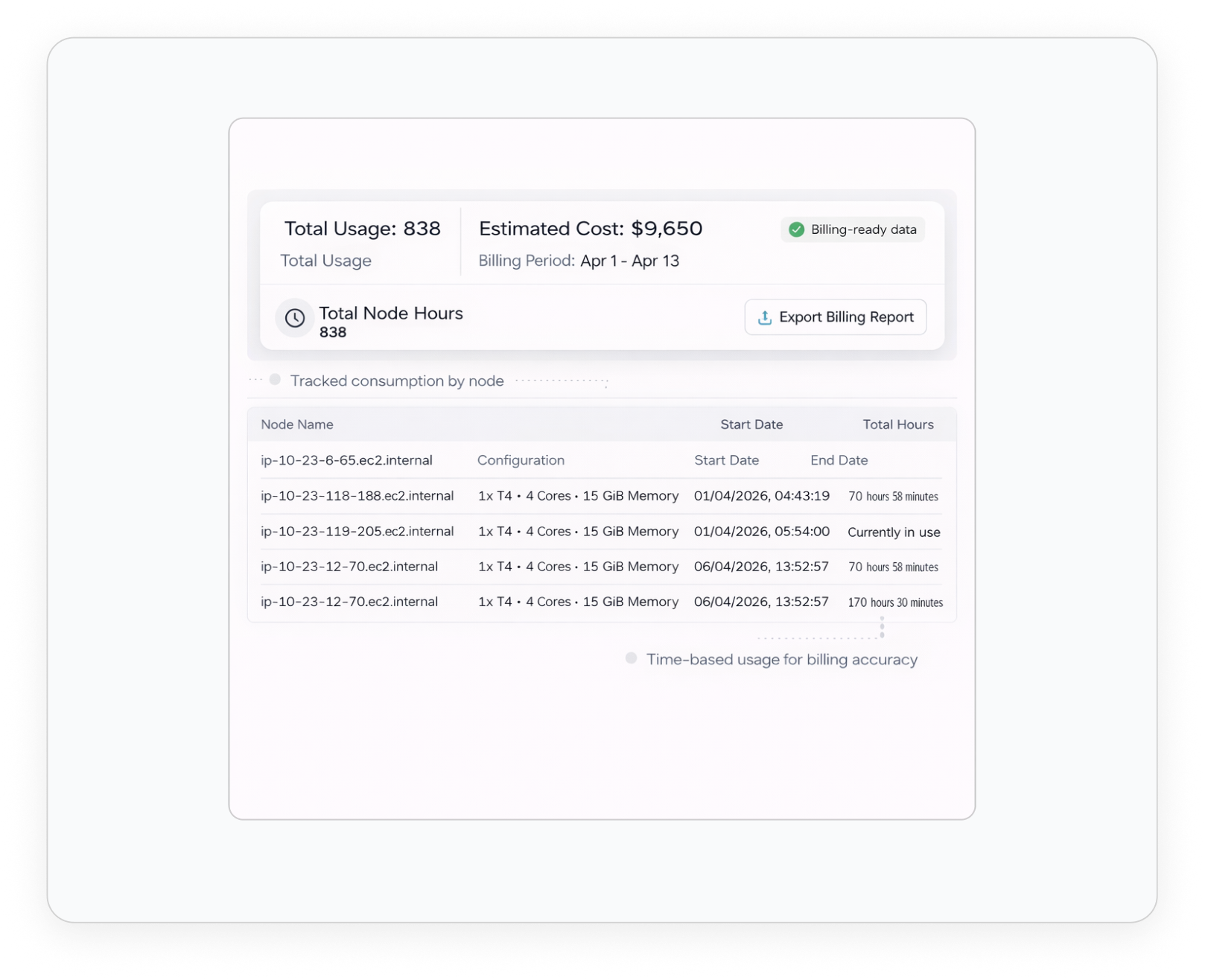
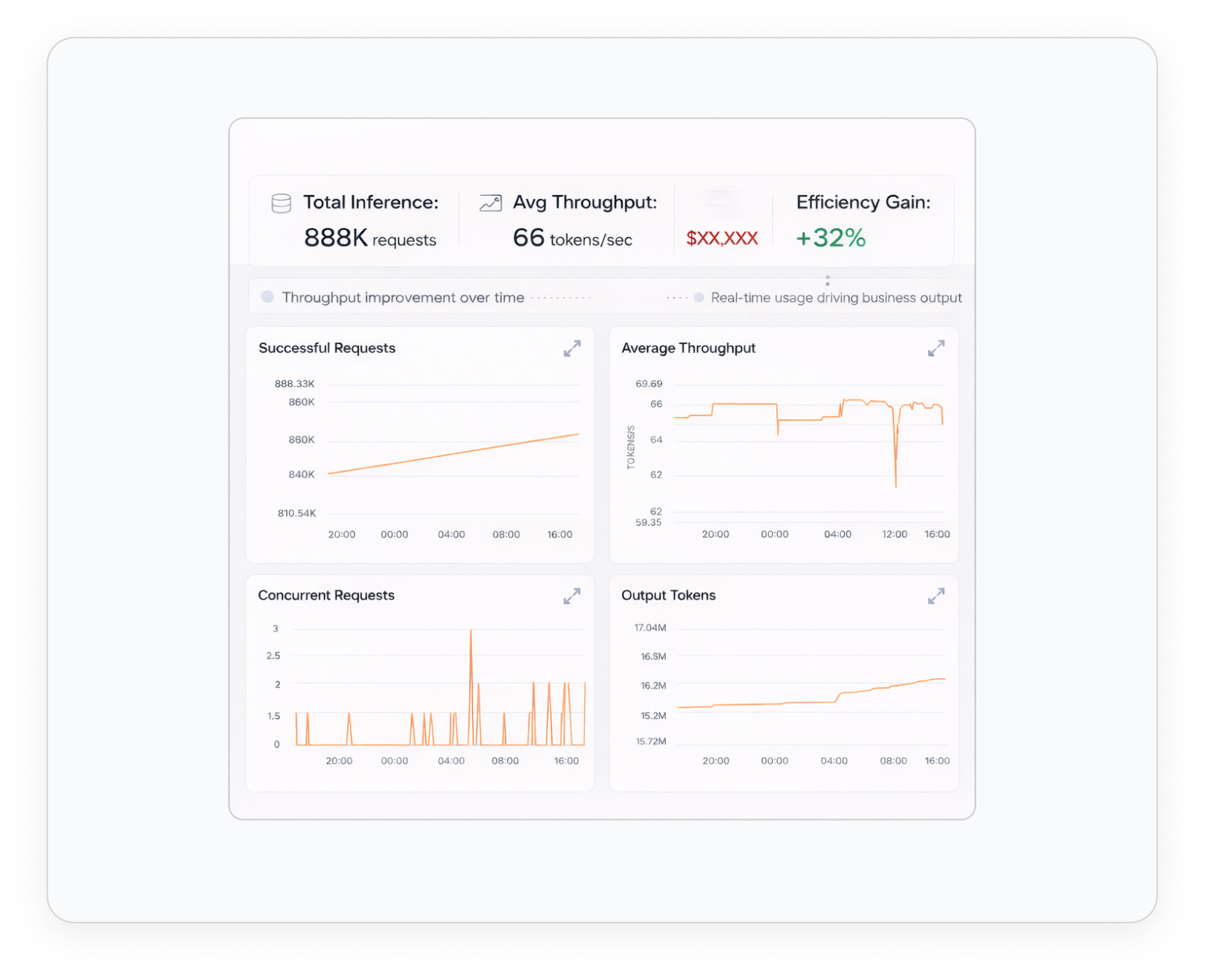
Dashboards & Reporting
Unified Visibility Across Allocations, Usage, and Cost Attribution. Connecting AI Investment to Business Impact
04
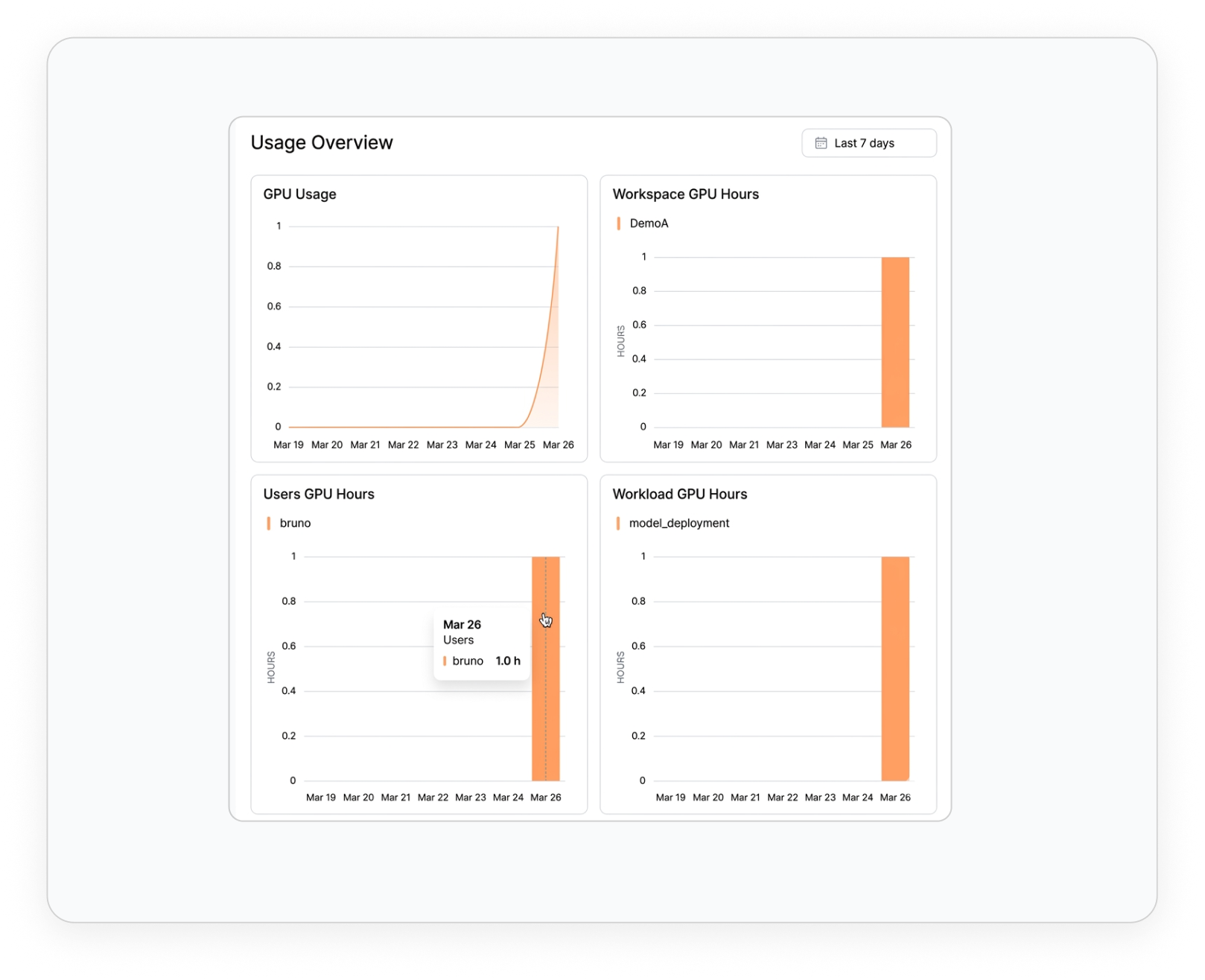
Monitoring and Logging
Real-Time Monitoring & System Health, Gain full visibility into nodes, GPUs, and workload performance
Our partnership with Open Innovation AI brings together all the critical building blocks for scalable LLM-based solution development. Their platform offers a clear blueprint for organizations worldwide to efficiently operationalize LLMs and accelerate the delivery of impactful, customer-centric AI use cases.
Renen Hallak
CEO and founder
We work closely with OI team to build AI clusters in the UAE. Their role in cluster orchestration and MLOps lets us focus on infrastructure delivery, together, we bring AI datacenters online faster.
Suleman Khan
SVP Partnership, WWT
Together with Open Innovation, we’re redefining how high-performance storage supports AI workloads. We're offering customers a data storage platform to enable scalable MLOps pipelines for the most demanding use cases.
Omar Akar
Regional VP, PureStorage
The OICM platform from Open Innovation AI enables seamless deployment and inference of our LLMs across high-performance GPU clusters. It simplifies the complexity of scaling and managing AI workloads, allowing us to focus on delivering faster, more efficient AI solutions.
Dr. Hakim Hacid
Chief Researcher, TII
By partnering with Open Innovation, we’re able to manage the complexity of AI infrastructure behind the scenes. The OICM platform lets our users access AI services without the infrastructure overhead. It means faster time to value, lower operational burden, and scalable services they can trust.
Josh Payne
CEO, Nscale
Commonly Asked Questions
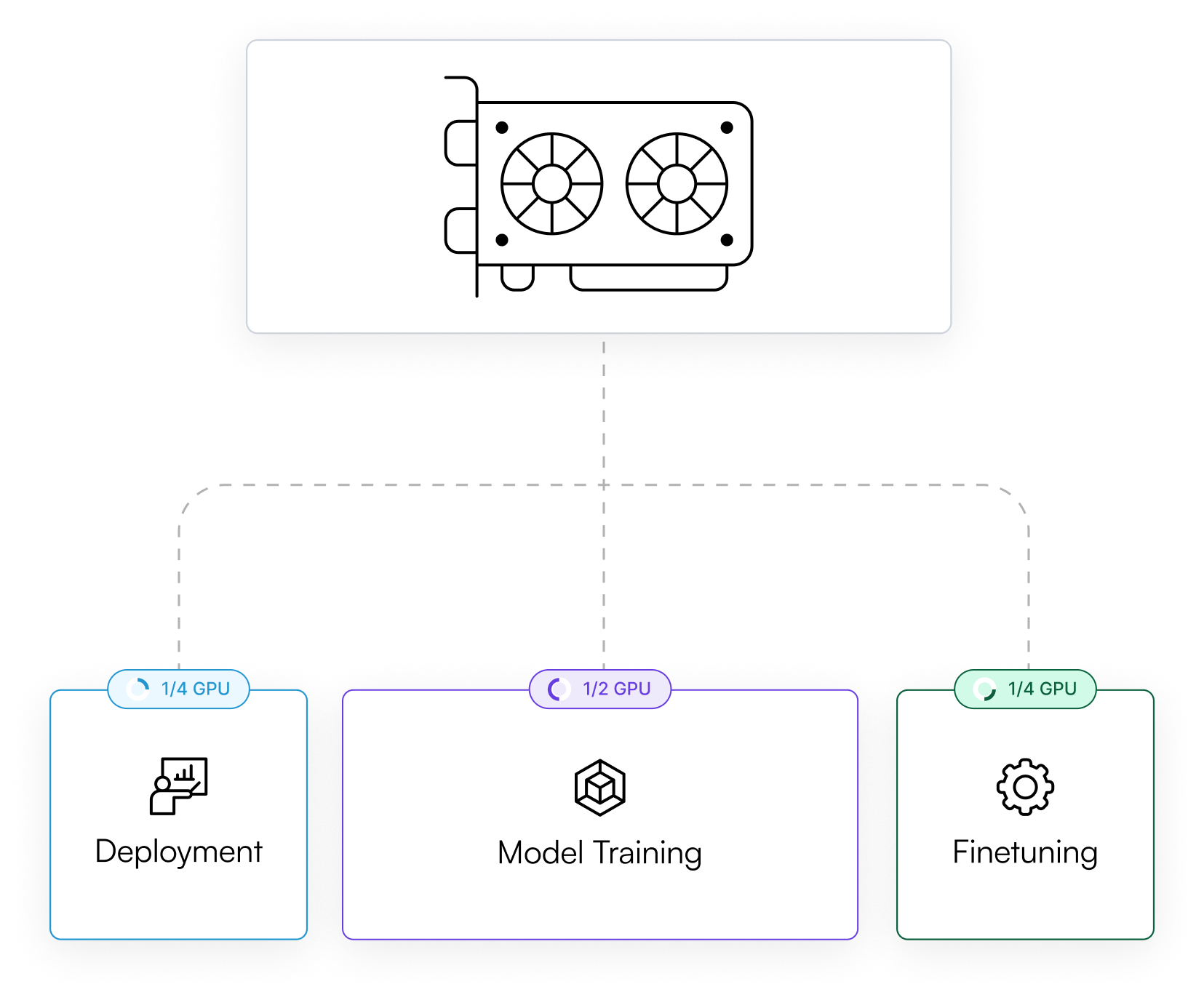
Can I allocate GPUs fractionally across jobs?
Yes, OICM supports fractional GPU allocation, enabling you to divide a single GPU into smaller portions (e.g., 1/2, 1/4) and assign them to different jobs to optimize GPU utilization.
How does multi-tenancy work in this system?
Each tenant operates in an isolated environment with dedicated namespaces or clusters, compute quotas, and role-based access control for secure resource segregation.
Can I monitor resource usage by workspace or tenant?
Absolutely. You can track usage metrics (CPU, GPU, memory) per workspace, or tenant, along with billing and quota visibility.
How is system health and performance monitored?
The monitoring layer provides real-time dashboards, logs, and alerting for all infrastructure components, including nodes, GPUs, agents, and jobs.
Which types of AI tasks can I do with OICM?
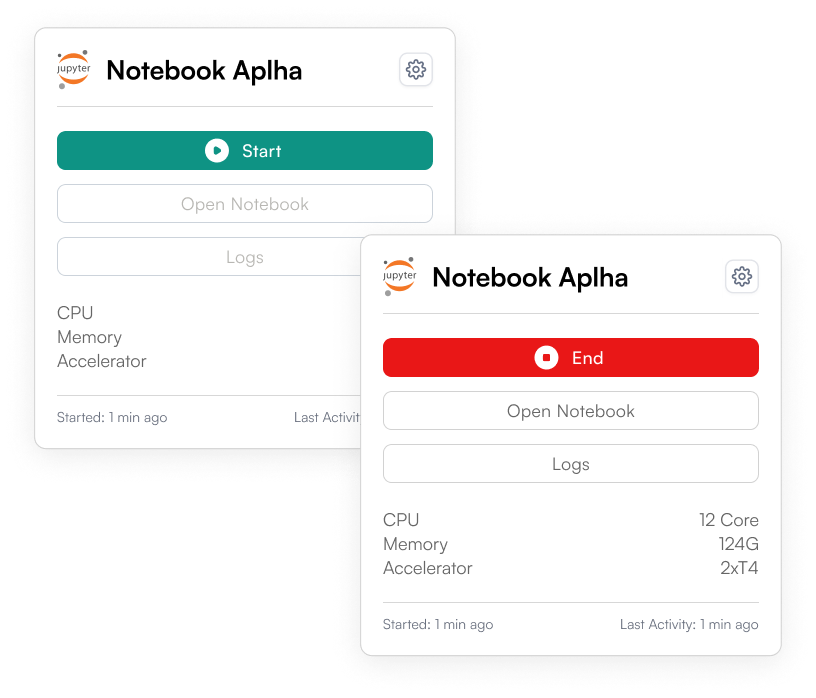
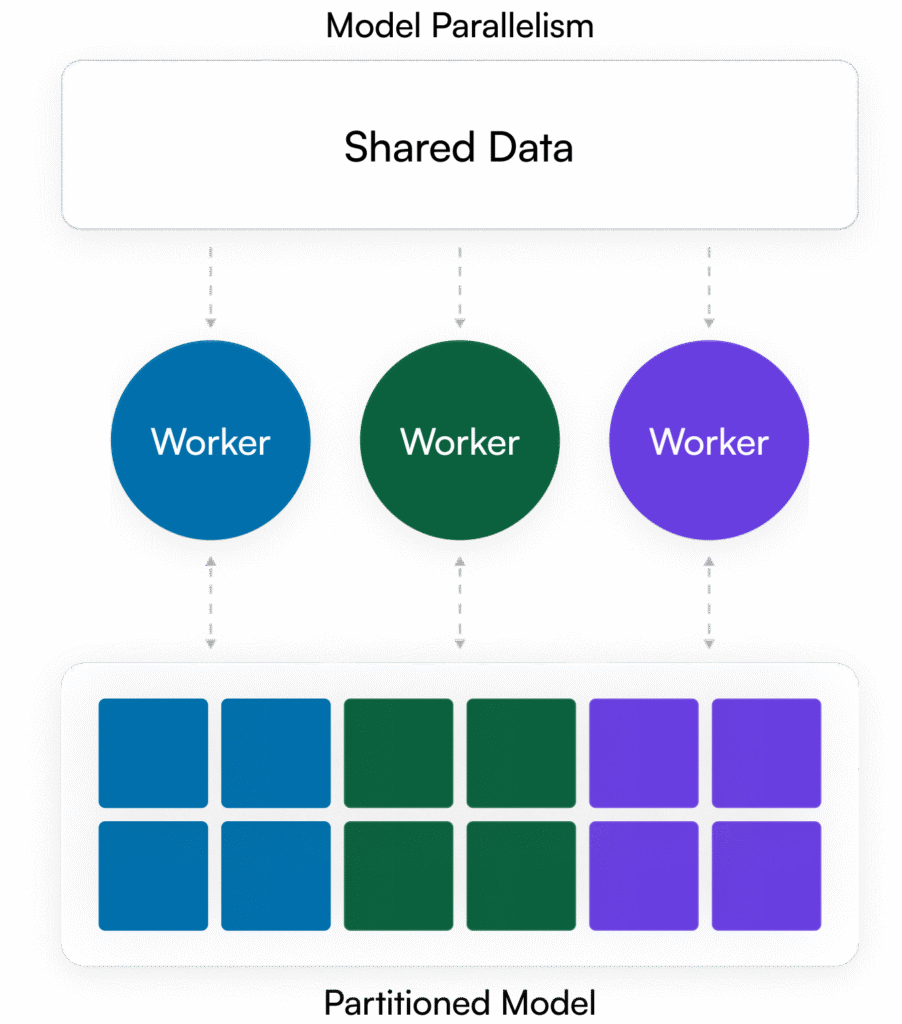
OICM supports the entire AI and machine learning lifecycle, from experimentation to production. You can use it to deploy, train and fine-tune models, run distributed training jobs and more. Once your models are ready, OICM helps you deploy them to production, conduct A/B testing between different versions, and benchmark their performance. It also provides a secure and GPU-optimized inference environment, along with managed Jupyter notebooks for data exploration and experimentation.
For more details, check out all of our features in the OICM documentation.
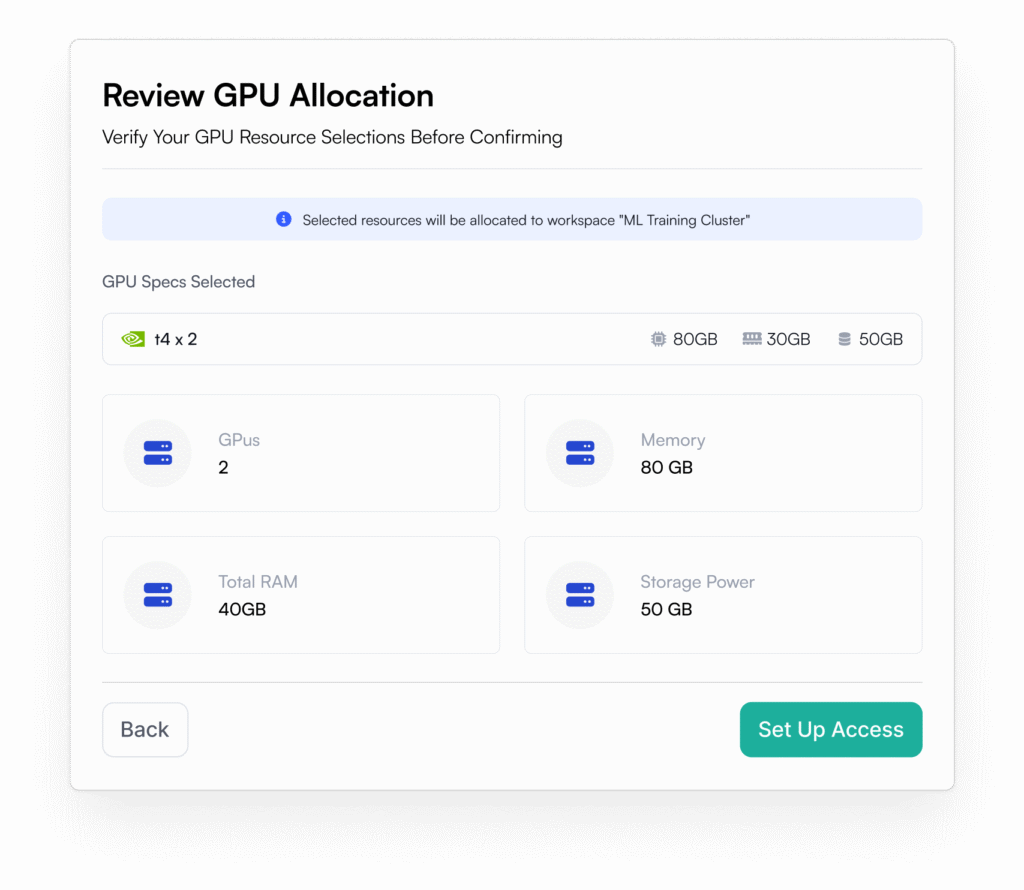
How do I enable access to GPU nodes for my team?
To enable GPU access for your team, your platform administrator first needs to onboard your Kubernetes cluster to OICM. Once onboarded, platform administrators can manage access and allocate GPU resources to specific teams or projects through the OICM portal. This ensures that GPU usage is controlled, secure, and aligned with your team’s needs. OICM gives you full visibility and control over how infrastructure resources are allocated and shared across your organization.
For step-by-step guidance, visit the OICM documentation