
Running AI workloads is straightforward.
Running them efficiently across multiple tenants, teams, and clusters is not.
When you build a multi-tenant AI platform, GPU allocation quickly becomes one of the most important architectural decisions you make. GPUs are expensive, workloads are bursty, and different teams have very different expectations around performance and availability.
For more than a year now, I’ve been working on AI workload orchestration in multi-tenant environments as part of building OICM, a multi-tenant AI infrastructure platform. The real challenge isn’t just deploying models or launching training jobs.
It’s deciding:
- Who gets access to which GPUs to run which workloads?
- How do you prevent one team from starving another?
- How do you scale without exploding costs?
- How do you enforce isolation without killing efficiency?
Let me share how we approached this.
The Real Problem: Multi-Tenancy + GPUs
A tenant is a group of users operating in isolation from other groups on the same platform.
A serious multi-tenant AI platform must guarantee that one tenant cannot impact another’s security and service availability. Data must remain strictly segregated. Compute boundaries must be enforced in a way that is not just logical, but operationally safe. Resource usage must be predictable and governed, not left to chance.
Now introduce GPUs into that equation.
GPUs are not just another compute resource. They are expensive, scarce, and often the primary cost driver of the entire platform. AI workloads are bursty by nature. Training jobs can consume large amounts of hardware for hours or days. Inference systems, on the other hand, demand predictability and low latency. Both expect priority, both assume availability.
When multiple tenants share the same infrastructure, you are effectively asking them to share some of the most valuable hardware in the system. You cannot rely on best effort scheduling or informal agreements. You need explicit boundaries, clear allocation rules, and deterministic enforcement.
Multi-tenancy with GPUs is not simply about isolating namespaces. It is about managing scarce, high-value compute in a way that protects availability, ensures fairness, and maintains trust across all users of the platform.
Hard vs Soft Multi-Tenancy
Isolation in multi-tenant platforms is not binary. It exists on a spectrum.
At one end, you have what is often called hard multi-tenancy. In this model, each tenant operates on fully dedicated infrastructure. Clusters are not shared. Compute is not shared. Network boundaries are explicit. The separation is physical or near-physical, which makes the isolation model easier to reason about. From a security and compliance perspective, the story is simple and clean.
At the other end, you have soft multi-tenancy. Here, tenants may share the same physical clusters and hardware. Isolation is enforced at higher layers through scheduling constraints, quotas, namespaces, network policies, and strict resource governance. The physical infrastructure is shared, but the logical boundaries are carefully controlled.
Soft multi-tenancy is typically more cost efficient. It allows better hardware utilization and makes it easier to scale incrementally. However, it requires stronger orchestration discipline. You cannot rely on physical separation to protect you. The platform must actively enforce boundaries.
Both approaches are valid. The right choice depends on customer requirements, regulatory constraints, and risk tolerance.
In OICM, we do not force a single model. Customers can choose the level of isolation that best fits their needs, whether that means fully dedicated clusters or controlled sharing within a governed environment.
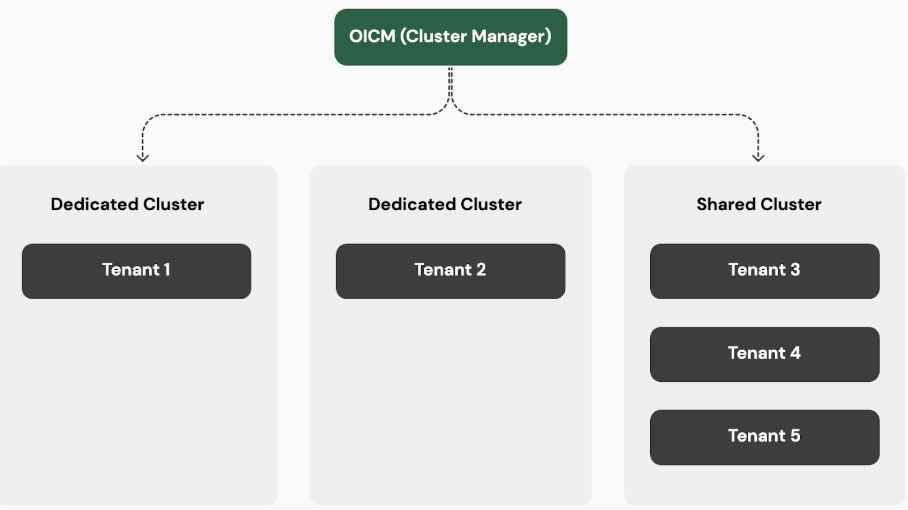
Even when clusters are shared, we enforce a non-negotiable boundary:
A node can only belong to a single tenant.
This means that while control planes and cluster infrastructure may be shared, the actual compute nodes and their GPUs are never shared across tenants. Node-level ownership significantly reduces cross-tenant interference, simplifies performance reasoning, and lowers security risk.
It allows us to preserve strong isolation guarantees without requiring every tenant to run an entirely separate cluster.
Resource Management Inside a Tenant
Isolation between tenants is only half the challenge.
Even within a single tenant, complexity quickly emerges. Most organizations are not a single homogeneous team. They consist of research groups, production owners, MLOps engineers, experimentation teams, and sometimes completely different business units, all sharing the same pool of hardware.
Now imagine a fairly typical setup:
- 2 GPU nodes.
- 8 H100 GPUs per node.
- 10 engineers.
A mix of research training jobs, production inference services, fine-tuning workloads, and experiments running in parallel.
On paper, the infrastructure looks generous. In practice, it becomes a coordination problem.
If you expose all GPUs equally to everyone, contention is inevitable. A long-running training job can consume most of the capacity. Production systems may suddenly compete with experiments. Researchers may need temporary bursts of compute. Meanwhile, the business expects predictable availability for customer-facing services.
This is where the real orchestration challenge begins.
You need to answer difficult questions:
- How do teams share GPUs fairly?
- How do you guarantee capacity for critical workloads?
- How do you prevent one group from consuming all resources?
- How do you allow burst usage without sacrificing control?
Solving multi-tenancy at the tenant boundary is important. Solving it inside the tenant is what determines whether the platform remains stable under real-world pressure.
Workspaces as Allocation Boundaries
Tenant isolation is only the outer boundary. Inside a tenant, when multiple teams compete for the same pool of GPUs if you simply expose all available hardware to everyone, contention becomes inevitable. To prevent this, we introduce allocation boundaries inside the tenant.
In OICM, the workspace is that boundary.
A workspace is a logical environment within a tenant that groups users, roles, and workloads under a shared governance model. More importantly, it defines resource constraints. Each workspace has explicit limits on storage, CPU, memory, and GPU usage.
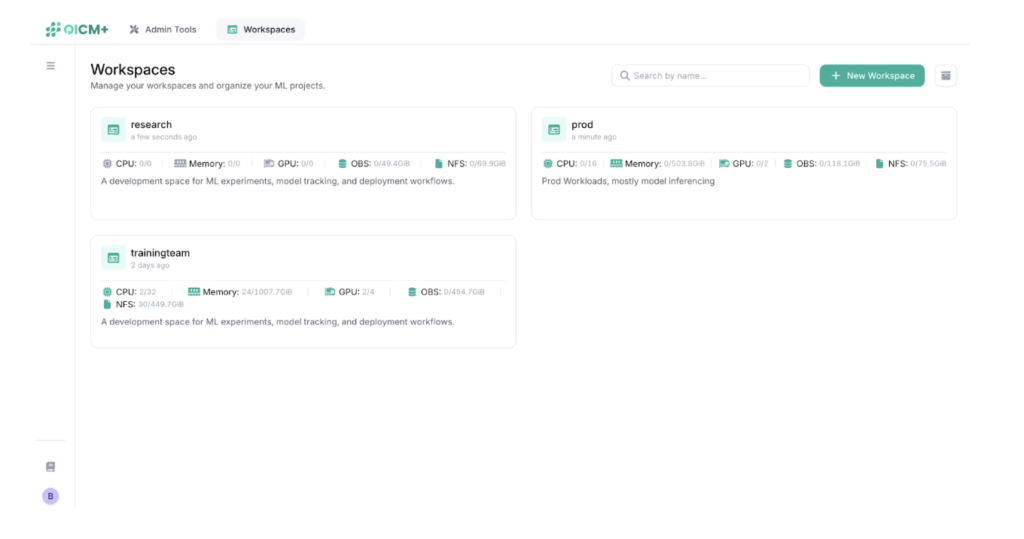
Instead of assigning GPUs directly to individual users, we assign structured capacity to workspaces. This creates accountability and predictability at the team level rather than the individual level.
Reserved Capacity and GPU Borrowing
Workspaces can reserve GPU capacity to guarantee availability for critical workloads. For example, a production workspace may reserve four GPUs to ensure inference systems remain stable under load.
However, static reservation alone leads to underutilization. Reserved GPUs often sit idle during off-peak periods.
To address this, we introduced GPU borrowing.
If a workspace has unused reserved GPUs, other workspaces can temporarily borrow that capacity. For instance, if production is idle, research workloads can scale up and consume those GPUs.
But borrowing is conditional.
The moment the original workspace requires its reserved capacity, the system reclaims it. Borrowed workloads are preempted or gracefully drained. GPUs are returned, and reservation guarantees are restored.
This approach creates a deliberate balance:
- Capacity is guaranteed when needed.
- Idle hardware is minimized.
- Fairness is enforced.
- No workspace can permanently capture resources beyond its allocation.
Borrowing is opportunistic, not permanent.
It allows us to maintain high utilization while preserving strict guarantees for critical workloads.
AI Workload Execution Flow
When an AI workload is launched, the orchestration layer evaluates several dimensions before scheduling:
- Workspace quota limits
- Reserved capacity
- Available Borrowable capacity
- Tenant-level node ownership
- Real-time GPU availability
Only if all constraints are satisfied does the workload get scheduled. Otherwise, it is queued or rejected. There is no silent overcommit and no hidden contention. Every allocation is explicit and enforced.
Why This Model Works
Efficient GPU orchestration in multi-tenant AI systems is fundamentally about balance.
You must protect isolation while maximizing utilization. You must enforce fairness without sacrificing performance. You must guarantee availability without wasting expensive hardware.
Node-level tenant isolation protects hard boundaries between customers.
Workspace-level quotas introduce structured governance inside a tenant.
Reserved capacity guarantees stability for critical workloads.
GPU borrowing ensures hardware is not left idle.
Together, these mechanisms allow the platform to scale in a controlled, predictable way without descending into resource chaos.
What’s Next: MIG and Fine-Grained GPU Slicing
So far, we’ve looked at GPU allocation at the node and workspace level. That already introduces meaningful design decisions around isolation, fairness, and utilization.
But modern GPUs add another layer of capability: MIG, or Multi-Instance GPU.
With MIG, a single physical GPU can be partitioned into multiple isolated instances. Instead of allocating entire GPUs, you can allocate slices of GPU capacity. This opens the door to much finer-grained control. Smaller workloads no longer need to consume an entire GPU. Utilization can increase significantly. Fairness models can become more precise.
At the same time, orchestration becomes more complex. Scheduling decisions now operate at the slice level. Capacity tracking must be more granular. Borrowing and reservation models must adapt to fractional resources. Isolation guarantees must still hold, even when hardware is subdivided.
In the next post, I’ll explore:
- When MIG actually makes sense
- The tradeoffs between full GPU allocation and sliced GPU allocation
- How to integrate MIG into a multi-tenant orchestration model without breaking guarantees
If you’re designing AI infrastructure for scale, this is where the architecture starts to evolve from resource allocation into true resource optimization.
These are the kinds of architectural decisions we’ve had to make while evolving OICM to support real-world AI workloads at scale.


