
Overview
Technology Innovation Institute (TII) is a leading applied research center in the UAE and the organization behind the globally recognized Falcon family of large language models.
As Falcon gained international attention, TII faced a strategic challenge: How do you move from publishing model weights and benchmark scores… to enabling real-world usage at scale?
TII needed a stable, production-grade environment that could provide public access to Falcon models while maintaining performance control, infrastructure governance, and operational stability.
The Challenge
Publishing foundation models is one thing.
Operationalizing them for global users is another.
TII needed to:
- Deploy Falcon models on high-performance GPU infrastructure
- Provide a public-facing chat interface for easy testing
- Support concurrent users without downtime
- Maintain predictable performance during benchmarking and live use
- Eliminate manual infrastructure overhead
- Protect institutional reputation through service stability
Without a managed orchestration layer, public access risked instability, limited adoption, and poor user experience.
The Solution
TII deployed Falcon inferencing environments using OICM as the orchestration and control layer.
OICM enabled:
- Centralized GPU orchestration across AMD MI250 infrastructure
- Multi-tenant, policy-based resource governance
- Standardized inferencing deployment workflows
- Real-time operational observability
- Stable public API and chat interface access
- Benchmarking-ready environments for performance validation
Users could test Falcon models through a simple interface without managing infrastructure or writing complex deployment code.
Measurable Impact
Over the course of the engagement:
- User base grew from 0 to +1000 active users
- Multiple Falcon models ran concurrently without downtime
- Stable throughput and latency maintained during live usage
- Real-time monitoring of:
- Streaming throughput
- Concurrent users
- Latency trends
- Success/failure rates
- Time to First Token
This stable, public-facing platform significantly expanded Falcon’s visibility beyond benchmark scores.
It transformed Falcon from a research asset into an accessible AI experience.
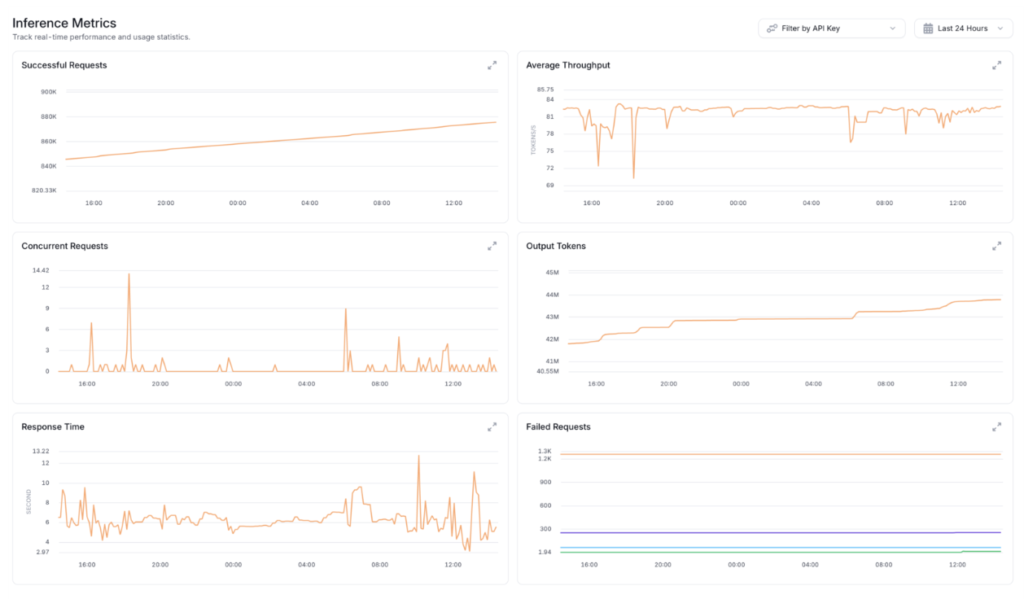
Example of Inference Observability
Falcon inference workloads were monitored in real time across key operational indicators to ensure stability and reliability during live usage. Observed indicators included:
- Request throughput
- Concurrent inference requests
- Response time and latency trends
The metrics shown below are provided as an example of inference observability and do not represent customer data or performance benchmarks.
Strategic Value Delivered
This deployment enabled:
- Public benchmarking critical for Falcon’s marketing positioning
- Increased global recognition through direct usage
- Improved user experience with zero-downtime reliability
- Lower barrier to AI adoption via APIs and chat interface
- Institutional confidence in public AI deployments
The stability of the platform reinforced Falcon’s credibility in a competitive global AI landscape.
Why It Matters
For leading AI research institutions, model development alone is not enough.
Operational access determines adoption.
This deployment proves that:
- Foundation models can be operationalized securely and reliably
- Public-facing AI services require orchestration and governance
- Infrastructure stability is a strategic asset
- AI democratization depends on production-grade control layers
OICM enabled Falcon to move from research breakthroughs to scalable user experience.
Explore This Approach for Your Organization
Every organization’s AI journey is different.
Let’s explore how this approach can work for your specific use case. Contact us!

