
This experiment demonstrates a sophisticated autoscaling approach using:
- FastAPI application
- Prometheus Pushgateway
- KEDA (Kubernetes Event-Driven Autoscaler)
- Custom request tracking metrics
When the application receives requests, it records active request counts (or active “user requests”) and pushes these metrics to the Prometheus Pushgateway. Prometheus (deployed via the kube-prometheus-stack) then scrapes these metrics and KEDA uses a Prometheus-based trigger to scale the number of pods according to the load.
Repository Link
Access the repository via the following link: Keda Autoscaling Prototype
How it works in our case?
Connectivity Between ScaledObject and Deployment
The ScaledObject in KEDA serves as a mediator between your Kubernetes workloads and the scaling logic derived from external or internal event sources, like metrics. Here’s how it connects to your Deployment:
- Reference to Deployment:
The ScaledObject includes a scaleTargetRef field, where you specify the target Deployment’s name and kind. This field indicates which Deployment should scale up or down based on the metrics the ScaledObject is monitoring. - Metric-Based Scaling:
The ScaledObject uses triggers—often based on metrics from Prometheus—to determine when the target Deployment’s replicas should increase or decrease. By configuring a Prometheus trigger, the ScaledObject queries a specified metric, such as the number of active requests, and compares it against thresholds. - Integration with Horizontal Pod Autoscaler (HPA):
Once the triggers fire, KEDA creates or updates a Horizontal Pod Autoscaler behind the scenes, adjusting the Deployment’s replica count. This ensures that as load or metric values rise, more pods are created to handle the demand, and as the metric falls, the cluster can scale down, freeing resources. - Fine-Grained Control:
The ScaledObject allows for setting minimum and maximum replica counts, ensuring that the Deployment remains within safe operating limits even as traffic patterns change. - triggers:
The triggers define what external metric or event KEDA should respond to for scaling decisions. Here, a single Prometheus trigger is configured.- type: prometheus:
Indicates that the trigger uses Prometheus metrics as the data source for scaling decisions. - metadata:
- serverAddress: Points to the Prometheus instance. In this case, http://prometheus-operated.kube-prometheus-stack.svc.cluster.local:9090 is the internal service address where Prometheus can be queried.
- metricName: A label for the metric KEDA uses internally to track scaling. This should be a unique name that identifies the metric.
- query: A PromQL query (sum(active_user_requests{model_id=”test-model”})) that retrieves the metric data from Prometheus. It sums all active_user_requests that match the label model_id=”test-model”.
- threshold (20): The main scaling threshold. When the metric reaches or exceeds 20, it triggers an increase in replicas.
- activationThreshold (10): Sets the lower limit at which scaling actions are considered. The Deployment will not scale unless the metric meets or exceeds a value of 10. This helps avoid unnecessary scaling actions when metrics are below this threshold.
- type: prometheus:
In essence, the ScaledObject is the glue that ties a metric-driven autoscaling policy directly to a Kubernetes Deployment, enabling dynamic resource scaling based on real-time application load.
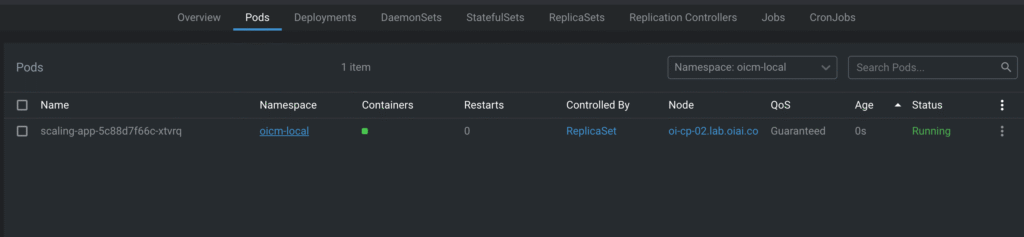
After the metric reaches or exceeds 20:
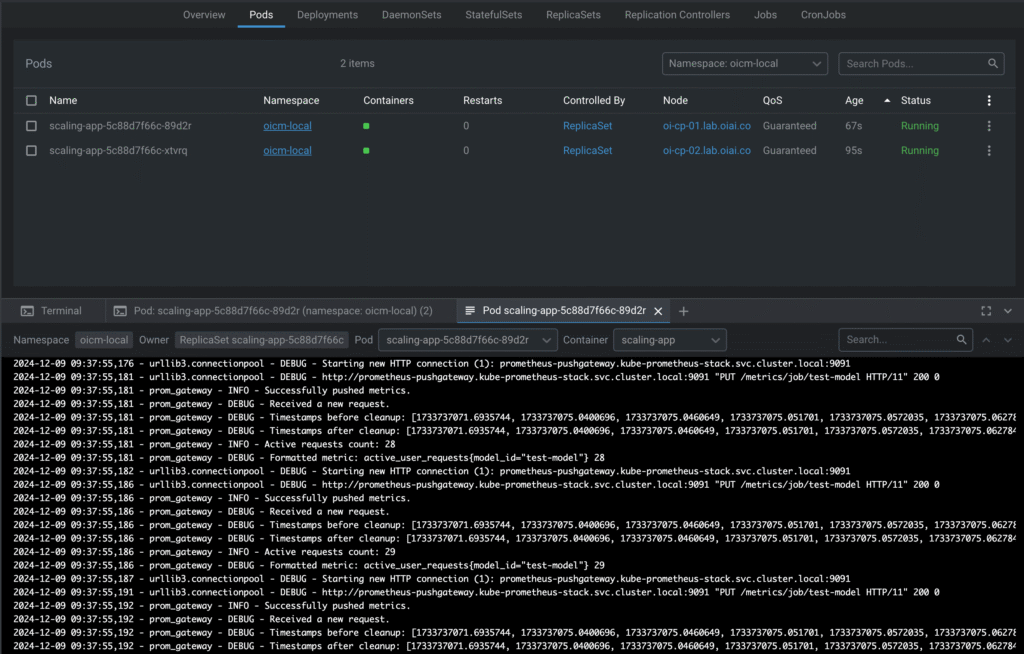
System Architecture
Components
- Application (app.py):
- FastAPI web service
- Tracks active requests using custom middleware
- Pushes metrics to Prometheus Pushgateway
- Metrics Gateway (prom_gateway.py):
- Manages request tracking
- Calculates active requests within a sliding time window
- Pushes metrics to Pushgateway
- Deployment Configuration:
- Kubernetes Deployment
- Service for exposing the application
- KEDA ScaledObject for dynamic scaling
- Stress Testing Tool (stress_test.py):
- Simulates concurrent user load
- Measures application performance and scaling behavior
Key Technical Details
Request Tracking Mechanism
- Uses a thread-safe sliding window approach
- Tracks request timestamps within a configurable time window (default 60 seconds)
- Pushes active request count to Prometheus Pushgateway
Metric Push Strategy
- Custom metric: active_user_requests
- Labeled with model_id for granular tracking
- Uses HTTP PUT to Prometheus Pushgateway
Autoscaling Trigger
- KEDA ScaledObject configures scaling based on Prometheus metrics
- Scales when active_user_requests exceeds 20
- Minimum 1 replica, maximum 10 replicas
- 15-second polling interval
- 30-second cooldown period
Prerequisites
Required Kubernetes Components
- Kubernetes Cluster
- KEDA Installed
- Prometheus Operator
- Prometheus Pushgateway
Troubleshooting
Common Issues
- Metric Not Pushing:
- Check Pushgateway connectivity
- Verify network policies
- Validate metric format
- KEDA Scaling Problems:
- Confirm Prometheus service URL
- Check KEDA operator logs
- Verify RBAC permissions
Implementation Proposal
We need to achieve the following:
- Auto scale the model based on a metric value
- There’s at least one pod running for the model (never downscale to 0)
- Scale based on a pre-defined config in the model version
- Scaling should be fast, as we shouldn’t download the model on each created replica
KEDA supports many scalers. For V1, we can use Prometheus only.
- Requirements:
- Auto scaling with the current deployment config will make it very slow, as there’s no shared volume between the different pods in the same model deployment. So, each time the a new instance is created, the model needs to be downloaded again. With large models (i.e 70B, 180B) this can take hours. So, as a first step we need to use PVC with model deployment replicas: MLOPS-2018 – Use PVC with model deployment replicas Closed
- Deployment images download: if the deployment image is not cached in the node, it can take up to 3 minutes to download in NVIDIA and 12 minutes in AMD (ROCm images are relatively large). So, all the time, these images must be cached on the nodes once platform is deployed on a new cluster. (TO BE DISCUSSED WITH THE INFRA TEAM)
- Metrics to start with
- number of concurrent requests, once implemented: MLOPS-1994 – Expose ML models metrics from inference API gateway (V2) Done
- Auto scaling config:
- a new section will be added to the model version where the user can configure the auto scaling scenarios. For instance:
- metric: dropdown list with the supported metrics for auto scaling (for v1 it’s only number of concurrent requests)
- threshold: number of “metric“ value per each instance. For example, if threshold is 10, 15 concurrent users will create 2 instances.
- min replicas: min value is 1
- max replicas
- a new section will be added to the model version where the user can configure the auto scaling scenarios. For instance:
- When to activate Auto-Scaling:
- Performance benchmark can affect the auto scaling as it can exceed the threshold and trigger another instance which is not needed and may affect the performance benchmark results. Performance benchmark is only allowed in the “stagging“ stage. So, we can just enable auto-scaling in the “production“ stage, where the performance benchmark is not allowed and it actually makes sense to just use auto-scaling in production.
Note: KEDA supports “activationThreshold“ which means the min value of the scaling metric after which the scaler is activated. For instance, activationThreshold: 20, threshold: 10. 15 users won’t create 2 instance as the scaler is not activated. To avoid this conflict, we will just use the threshold only for now.



